bacula in the enterprise part 1
2011-07-22
I’ve been using Bacula, the open source backup software, for over a year now. Things have been going well, and I would like to dedicate a post or two to the environment I built.
Background
Over a year ago, I took it upon myself to replace a single Legato Networker server with Bacula. One of our collaborators had decided to ship us (for no reason at all really, I think they were cleaning out their data center) a Sun X4200 AMD server, and two StorageTek/Sun NAS servers.
I had no reason for the NAS heads, but the JBOD was full of drives and the Sun X4200 was useful enough. So, I gutted them (Since the StoragTek NAS heads were identical in almost every way to a standard X4200), put as much memory and CPU’s as I could in one system. This was my first Bacula server. It had around 2TB of FC storage and it made a nice replacement backup server for the 50 or so clients that were on the Networker server. The OS was not Solaris, as you might guess since I was using Sun hardware, but FreeBSD.
Since was focusing only on disk based backups, and FreeBSD has two fantastic large file systems (UFS2 and ZFS), this was my underlying storage platform. Combine that with the current choice of software (in the case, Bacula 5.0.x and PostgreSQL 8/9) from the Ports tree, it really makes the perfect open source software and hardware stack.
After spending a good amount of time wrapping my head around Bacula, and really, just carelessly diving into it, I was very happy with how fast and stable it was shaping up to be.
Around the same time, I was asked to pick up the project that literally went no where for years: The dreaded Backup Project for all of the S&T directorate. A mix of all OS’s, desktops, servers, laptops, etc… and around 3000 active machines online with lots of important data.
No small feat, and there are many reasons why this had been a difficult project to wrangle. One thing for sure, is we knew we had a lot of unique programmatic data.
I knew what software I wanted to use, and I was pretty set on using commodity hardware and reasonably priced storage. The next part was to define some constants in the environment.
The Initial Concepts
First up, I knew of the largest painful aspects of our computing environment:
- Budget constraints - We are not rich, and IT always seems to be underfunded. This project had to be as frugal as possible, yet still deliver.
- Diverse platforms - We have Windows, OS X and a mix of RHEL and Ubuntu for desktops. Server platforms range all across the board: Windows, OSX, RHEL, Solaris, FreeBSD, AIX, etc…
- Mission critical data - Lets face it, the Lab doesn’t make a car, or a VCR. We have a LOT of critical scientific knowledge that is only stored in bits and bytes. That is our product, scientific data that is truly unique.
- A campus like geography - the Lab is 1 sq. mile with a mixture of trailers, new buildings, and some buildings that are over 50 years old. The network backbone ranges from 10Gbps to 10Mbps. The poses a problem when it comes to backups.
With this in mind, theses are some of the initial concepts I latched onto:
- A distributed disk based storage backend for Bacula
- Smaller retention window - 1 month
- Reduce the amount of data that has to even go over the network
- Skip “reproducible data” such has installed programs like Office, and exclude the OS itself
- Enable client side compression. The effectively distributes the compression for all clients. Saves a lot of disk space :)
- Skip virtual machine images, like vmdk and vmem files, and treat important virtual machines as separate clients.
For Bacula itself, I had decided that each client would have its own resources. Very little is shared between each client, so for example client-001 would get all of these resources:
- Pool = “Client-001-File”
- Storage = a randomly assigned drive on one of the storage nodes
- Maximum Volume bytes = 10Gb
- Maximum Volumes = 100
- AutoPrune and Recycling enabled
- Job = “client-001” (one for backup and one for restore)
- FileSet = “client-001 FileSet”
What this prevents is cross-client data contamination. What is also prevented, and I found out later, was concurrent backups. More on that later though.
After feeling a bit more comfortable with a simple all-in-one server, I was ready to spec out new hardware. This was good, because at the same time it was our end of year budget crunch, and hardware had to be procured.
The Hardware
For storage, I had a few concepts I was floating around.
One, was to use MooseFS, a distributed filesystem , across a bunch of cheap node with a modest amount of storage.
The other, idea was to buy a handful of servers with a lot of internal storage, around 18TB or so. Them distribute them across the “campus” as a kind of Bacula storage node cloud.
The last idea was to take a more traditional backup server approach, and buy a server with as much expandable storage as possible and back everything up to that.
In the end, when a bunch of hardware showed up (I had some control over the hardware, but not all aspects since some of the managers took it upon themselves to purchase everything), I scrapped the MooseFS idea after talking it over with Jenny, and we took the last two: 4 HP servers with 17TB or RAID6 internal storage, and a large 140TB SAN array (Winchester Systems, great stuff!) as the primary backup node:
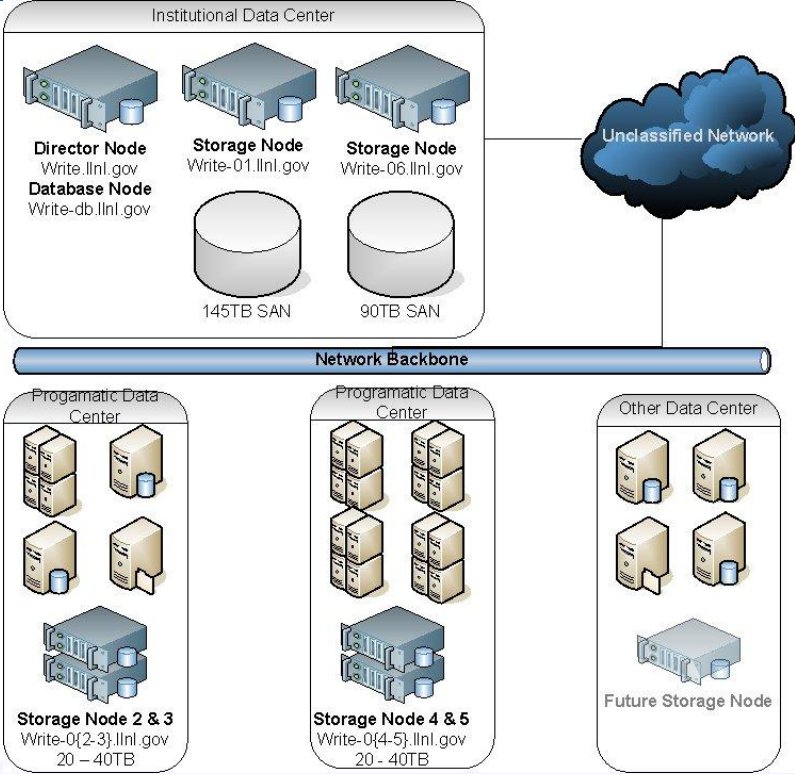
Our Environment
This model served us well for a while. We had a primary storage node that backed up a users primary desktop, and the smaller storage nodes were used to back up servers and infrastructure data.
There was room for improvement right away though. As soon as it was in production, I quickly mapped out what I felt were the next steps in making a robust backup environment.
More on that in another installment :)